
Zapewne każdy z was spotkał się kiedyś z sytuacją gdy zamiast tekstu na stronie lub pojedynczych liter pojawiły się dziwne znaki. I nie mam tu na myśli, że tekst był napisany np. po Chińsku. Od razu powiem, że to nie powód do paniki. Tylko informacja, że strona lub czasem plik mógł zostać zapisany z nie właściwym kodowaniem znaków.
Kodowanie znaków na stronie internetowej?
Prawidłowe kodowanie strony jest bardzo istotne. I to zarówno te w jakim zapisany został plik jak i to, które zostanie podane w nagłówku <head>. Jak nietrudno się domyśleć kodowanie to ustawione jest domyślnie na języka Angielski. Zakodowane są więc tylko litery standardowo występujące w tym języku (czyli należące do czystego alfabetu łacińskiego).
W przypadku np. języka Polskiego pojawi się więc problem z literami diakrytycznymi czyli np. ą, ę, ś, ć, ł, ź, ż. Znaki te nie występują bowiem w alfabecie łacińskim. Powoduje to, że w monecie kiedy przeglądarka próbuje odczytać stronę jeśli ma ona złe kodowanie (często domyślne) listery zostaną źle wyświetlone.
Czym jest kodowanie znaków?
W przeciwieństwie do nas przeglądarka internetowa bowiem widzi każdą literę lub znak w formie zbioru liczb binarnych (0,1). Dopiero później na podstawie informacji zamieszczonych na stronie odpowiednio to interpretuje.
Tak więc kodowanie znaków to przyporządkowanie odpowiednim liczbą odpowiednich znaków. Jednak było to możliwe musi zostać wybrany odpowiedni alfabet. Jednak to nie wszystko, plik musi zostać również zapisany w odpowiednim formacie z adekwatnym kodowaniem.
Zasada jest zbliżona do tego jak dobiera się krój pisma – jeśli dany font nie zawiera litery nie zostanie ona wyświetlona. Ewentualnie pokaże się jako inny znak np. jako prostokąt.
Przykład kodowania zdania
Przykładowo zdanie „Ala ma kota” zostaje zakodowane (widoczne dla przeglądarki) w następujący sposób:
| znak | numer | numer zapisany binarnie |
|---|---|---|
| A | 65 | 0100 0001 |
| l | 108 | 0110 1100 |
| a | 97 | 0110 0001 |
| (spacja) | 32 | 0010 0000 |
| m | 109 | 0110 1101 |
| a | 97 | 0110 0001 |
| (spacja) | 32 | 0010 0000 |
| k | 107 | 0110 1011 |
| o | 111 | 0110 1111 |
| t | 116 | 0111 0100 |
| a | 97 | 0110 0001 |
| . | 46 | 0010 1110 |
Przykład błędu kodowania znaków
By nieco jaśniej wyjaśnić o co mi chodzi przygotowałam bardzo prosty tekst do którego dodałam kilka Polskich liter. Dla jasności „stronkę” przygotowałam w notatniku.

Zdecydowałam się na notatnik ze względu na to, że to bardzo proste narzędzie. I wybranie formatu kodowania pliku nie będzie trudne. Jak widać na załączonym obrazku podczas zapisu mamy opcję wyboru kodowania w kilku zestawach. Domyślnie jest to jednak ANSI. I takie kodowanie zostawię (dla stron lepiej używać UTF-8).
Dodawanie informacji o kodowaniu na stronie
Jednak samą informację o kodowaniu ustawię na:
<meta charset="Windows-1252">

Jak widać definitywnie jest tu coś nie tak! Powodem tej sytuacji jest to, że przeglądarka odczytała charset="Windows-1252" i tak zinterpretowała stronę.

Teraz zmieniam na UTF-8. Kodowanie, które aktualnie jest standardem przy budowie stron. Oznacza to, że każdy program, edytor przeznaczony do budowy stron będzie domyślnie zapisywał w tym formacie.
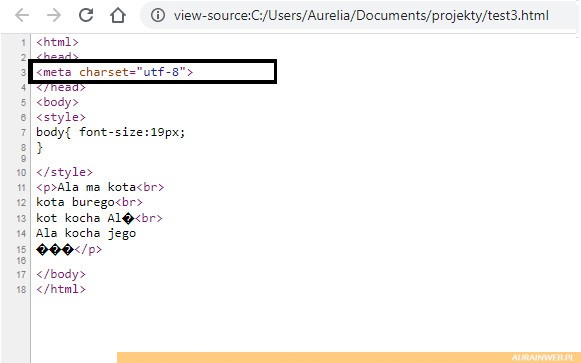
Nawet nie muszę pokazywać jak wygląda strona. Zamiast polskich liter pokazały się dziwne znaczki. Powodem jest to, że w dalszym ciągu mamy ustawione nie właściwe kodowanie samego pliku.
W celu odzyskania Polskich liter trzeba teraz konwertować plik na UTF-8. Po konwersji litery powinny zacząć wyświetlać się poprawnie.
Jak sprawdzić jakie kodowanie ma plik
Do tego celu posłużę się np. programem Notepad++ (jest to bardzo prosty w obsłudze edytor kodu). Po jego instalacji jedyne co muszę zrobić to otworzyć w nim plik, którego kodowanie chcę sprawdzić. Następnie z górnej belki wybieram opcję „Format”. Aktualny format to ten z „kuleczką” z boku.
W tym miejscu możemy również konwertować plik na inny format niż mamy obecnie.

Informacja o kodowaniu dostępna jest również u dołu po prawej stronie w tym edytorze np.:
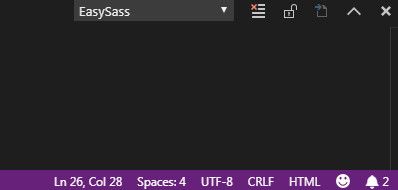
Kodowanie można też podejrzeć np. w Visual Studio. Informacja o kodowaniu pliku znajduje się na dolnej belce.
Standardy znaków
Jak nie trudno się domyśleć jest ich kilka. Obecnie najczęściej spotykanym na stronach formatem znaków jest UNICODE. Najłatwiej można to sobie wyobrazić jako tablicę / bazę różnych znaków i liter. Do jego odczytu wykorzystuje się kodowanie np. UTF-8, UTF-16 i UTF-32. W zależności od tego, na które się zdecydujemy przeglądarka użyje innego znaku (umieszczonego w określonej lokalizacji). Dlatego wiec użycie złego kodowania powoduje pojawienie się błędów.
Przykłady kodowania:

Obecnie UTF-8 jest standardem stosowanym np.
- pakietach biurowych
- na stronach internetowych
- w wielu aplikacjach oraz programach
Powodem tego jest duża ilość różnych znaków. W tym znaków specyficznych dla wielu różnych językach (takich jak Polskie litery lub Niemieckie). Zastosowanie jego oszczędna więc sporo czasu twórcom (nie muszą zmieniać kodowania pod konkretny kraj).
Kodowanie w ASCII
Prace nad nim zaczęły się 6 października 1960 – jako podstawę jego użyto kodu telegraficznego. Pierwsza wersja ASCII (American Standard Code for Information Interchange) została jednak udostępniona dopiero w 1963 roku. Metoda ta okazałą się dużo lepsza i łatwiejsza w obsłudze od wcześniej stosowanych. Dzięki czemu odniosła bardzo duży sukces. Z biegiem lat ASCII ulegał zmianom a konkretnie został aż czterokrotnie zaktualizowany.
ASCII zawiera: małe i wielkie litery alfabetu łacińskiego, cyfry, znaki przestankowe oraz inne symbole. Został on jednak stworzony z myślą o języku Angielskim. Dlatego też pominięto w nim różne litery, których nie ma w tym języku. Aż do roku 2007 roku był to najpopularniejszy standard stosowany w Internecie. A zastąpiono go UTF-8.
źródła:
- https://www.flynerd.pl/2019/09/kodowanie-znakow-ascii-unicode-utf-co-to-znaczy.html
- http://kursdlaopornych.pl/iso-ascii-unicode-kodowanie-znakow/